经济观察报 关注
2024-05-25 12:09

![]()

经济观察报 记者 任晓宁 钱玉娟 周悦 又有玩家加入了大模型价格战。
5月22日,腾讯云宣布大幅下调旗下主力大模型混元系列的价格。当天,科大讯飞也宣布降价,它的策略和腾讯相似,轻量模型免费,高性能模型降价。
大模型(LLM,Large Language Model),即具有大规模参数和复杂计算结构的机器学习模型,代表着当前AI技术的主流方向,也是国内外互联网公司重点布局的AI产品。
自5月15日字节跳动宣布旗下豆包大模型价格“以厘计费”以来,这场大模型价格战愈演愈烈,阿里巴巴、百度等国内互联网大厂相继选择参战。
与之形成鲜明对比的是,多家大模型初创公司选择了不降价的策略。截至发稿,除智谱AI以外,其他大模型明星初创公司——百川智能、Minimax、月之暗面、零一万物并没有调整价格。同时,智谱AI的大模型价格在下调后仍高于大厂。
国金证券互联网传媒首席分析师陈泽敏告诉经济观察报,这些公司此次选择大幅降价,是看到了大模型第一性原理——尺度定律(Scaling Laws)的释放,未来算力成本可能会更便宜。所以他们现在提前降价,先把自己的生态搭建起来。
谈及大模型初创公司面对价格战的不同选择,陈泽敏说,降价或者不降价都可以理解。像智谱AI这种在B端(企业客户)有优势的厂商,就没必要彻底参与价格战。
图1:近期国内厂商大模型价格战情况
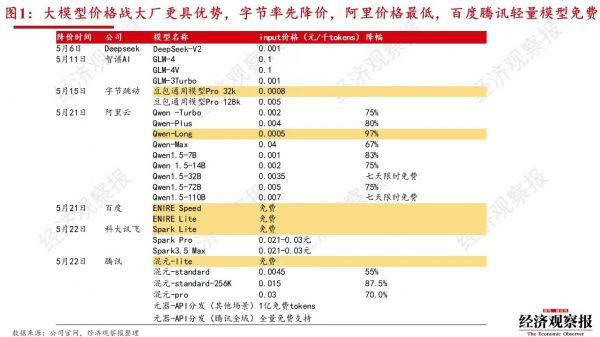
数据来源:公司官网,经济观察报整理
大厂为何争相降价
多家企业在宣布大模型降价时,都提到了技术进步带来的成本下降。
百度董事长兼首席执行官李彦宏曾表示,与一年前相比,百度旗下文心大模型的推理性能提升了105倍,推理成本则降到了原来的1%。字节跳动旗下火山引擎总裁谭待也提到,该公司可以通过混合专家模型(MoE)、分布式推理等技术手段,优化豆包大模型的推理成本,不会走用亏损换收入的道路。
创新奇智是一家企业级AI解决方案供应商。该公司首席技术官张发恩认为,技术进步的确推动了大模型推理成本的下降。一方面,得益于芯片技术的不断突破,单位算力对应的成本在下降。“打个比方,原来(购买)单位算力需要1块钱,现在5毛钱就能买到。”另一方面,现在大模型的量化压缩技术也越来越先进。以前运行一个80亿参数的大模型,一般需要16GB的显存容量,现在只需要4GB。
不过,张发恩强调,技术进步可帮助推理成本每年下降到原来的1/2左右,大模型的降价幅度却是以10倍来计算的。技术进步不是游戏规则改变的主要原因,商业决策才是本次降价的根本原因。企业希望尽快获得更多客户,占据更多市场份额,未来业务规模做大了,再去想办法挣其他的钱。他还认为,当前大模型技术的场景渗透率还很低,价格战并不明智。
经济观察报注意到,目前降低的只是调用大模型应用程序编程接口(API)的费用。与这一费用相比,客户使用云服务后,付费环节更多、付费额度更高。
以百度云的千帆大模型平台为例,虽然有两款百度旗下的大模型可以免费调用,但是模型部署、精调、评估、数据管理、插件调用等环节都需要按量付费。以最基础的模型部署为例,客户租赁5天私有资源池至少需要7000元。
阿里云在大模型降价后的第二天,就推出了上云优惠的组合拳,包括首次推出5亿元算力补贴,以及为200余款云产品制定折扣价,这些产品包括覆盖显卡(GPU)云服务器、大模型训练与推理服务等产品。
AI智能体(AI Agent)平台公司澜码科技的创始人周健认为,国产大模型正处在“烧钱换数据,竞争优质数据”的阶段。他称,大模型厂商实际上在烧钱进行大量的投入,多数厂商不太考虑定价能否覆盖住成本或带来利润。从商业策略层面看,现在大模型厂商展开降价的主要目的是收集更多样的数据。“竞相降价的现象,不能说是一个噱头,(厂商)互相之间在竞争数据,他们希望能够有更多的开发者基于各自的大模型去开发应用。”周健说。
使用者更看重性能
尽管价格战打得火热,但一些使用大模型的业内人士告诉经济观察报,与价格相比,他们更看重大模型的性能。
齐心集团是一家企业对企业(B2B)办公物资服务和软件即服务(SaaS)云视频企业。该公司的首席技术官于斌平说,他的团队从去年5月开始正式使用大模型,然后不断地对百度文心大模型和GPT模型(美国AI公司OpenAI旗下的大模型)进行调试,会调用大模型的API,也会在云上做自己的预训练和精调。
在将模型的准确率从80%多调试到90%多的过程中,于斌平发现,越往后调,越能发现模型能力存在的差异。在常见的聊天、文档摘要、翻译、智能客服这些功能上,大模型的推理、泛化能力可能差不多。但齐心集团需要将大模型应用于生产场景,对它的实际推理能力要求比较高。
从AI三要素来看,于斌平也认为大厂的大模型有较大优势。他说,在算法上,厂商的差异不大,大家都有一些好的工程师。在算力上,大厂投入较大,具备优势。在数据上,因为训练大模型需要公共数据,做搜索业务的百度,优势明显。
于斌平称,他的团队使用的百度文心大模型4.0,并不在此次降价的范围内。但即便有厂商推出更便宜的大模型,他们也不打算更换,这不仅是由于文心大模型4.0足够强大,也是因为他们在前期调试大模型的过程中付出了太多精力。
在为澜码科技选取大模型时,周健会考虑价格因素,但他更关注模型的质量、推理能力、参数和准确率。“在客户算力有限的情况下,不同的参数、准确率,决定了我们能够处理的项目规模。”周健说,不同的模型还会形成不同的客单价。此外,模型的连续性也会影响应用开发,例如更新速度是否足够快,都在一定程度上对应用的能力、竞争力以及能否满足市场需求有影响。
在周健看来,国内大模型厂商降价,对产业内的应用开发商带来了直接影响。“过去成本高昂,开发商需要考虑token(大模型文本中的最小单位)的费用,许多尝试受到限制。”大模型价格一旦降至“以厘计费”,甚至免费,应用开发商的成本曲线将大幅下降,这将促使他们更容易进行开发、试错,从而找到一些适用于大模型时代的AI原生应用。
初创公司要找对场景
零一万物创始人李开复和百川智能创始人王小川都对大模型初创公司加入价格战持否定态度。他们认为成本并不是客户选择大模型的唯一因素,企业和开发者也会综合考虑性能、市场、安全、需求等因素。
李开复认为大模型的性能优势是关键。他预计推理成本将会以每年10倍的幅度降低,但是疯狂降价是双输,他不会靠贴钱、赔钱去做生意。对需要最好模型的客户来说,购买100万个tokens的资源包,支付几元或者十几元的费用差别不大。王小川也表示不会参与价格战,他判断大厂降价实质是云厂商的新战争。大模型初创公司没有云服务的生态优势,不需要和大厂竞争价格,也不需要和其他中小企业竞争垂类赛道应用,而是要做一款超级应用。
一位与多家大模型厂商有合作的互联网大厂人士称,缺少落地场景是很多大模型厂商存在的通病。当大厂投入补贴来抢用户时,那些缺少模型差异化能力又没有商业化模式的大模型初创公司会被直接“卷死”。
据上述互联网大厂人士透露,某家大模型明星初创公司旗下的C端(个人用户)产品,每计算一次的成本高达一百多元。他并不怀疑该产品在某些细分场景的能力表现,但综合来看,它的能力并没有明显地超越阿里通义千问模型、百度文心大模型,甚至它还缺少可验证商业化的场景。当阿里、百度等大厂拉响大模型低价警报时,“它还不考虑生存的话,下一轮融资都没有了”。
上述互联网大厂人士还称,在大模型初创公司中,他比较看好智谱AI这类在B端场景里专注行业赋能、并在模型层继续向上走的厂商,以及像Mini Max这种已经找到了属于自己的C端场景的厂商,这些商业模式清晰的公司才是能长久生存的。

 京公网安备 11010802028547号
京公网安备 11010802028547号
 购物车
购物车


 订阅
订阅



